
Often, I need to quickly clone or explore from among hundreds of private github repositories I have access to via a github organization, from the command line. Rarely can I remember the exact name of the repository I'm looking for. Usually though, I do have a good idea of a word or two that is a part of that full repo name.
Recently I've been going full steam ahead on the fzf train, and it has been helping me find things with only pieces of the full name . . . so I thought: "Hey, what would it look like to leverage fzf for this?"
fzf is a command line tool that accepts a streamed in list of 'choices' and presents a continually updated UI for a user to type-ahead 'fuzzy' match against those choices. When a choice is selected, it is written to stdout. You can imagine how this fits with unix command chaining to serve all kinds of needs.
Initial Goals
To get started, I wanted to keep in a mind some goals for the project:
- The user should only have to type a few consecutive characters from the repo name to narrow in on a result.
- It should feel more responsive than the alternative -- popping open a browser and navigating the Github Web UI.
- It should match against all repositories in an organization, including those that were created even moments ago.
- It should match against public and private repositories in an organization, given the right auth/permission.
Version 0 - Is it possible?
First up, I tried hitting the Github API and piping the result to fzf to see what that would feel like. Initially I tested with my user public repositories.
Command:
$ curl 'https://api.github.com/users/mattorb/repos' | jq '.[].full_name' | fzf
Results:
This looks pretty good. At this point, I thought I might be close to done.
So . . . I tried a larger github org:
Command:
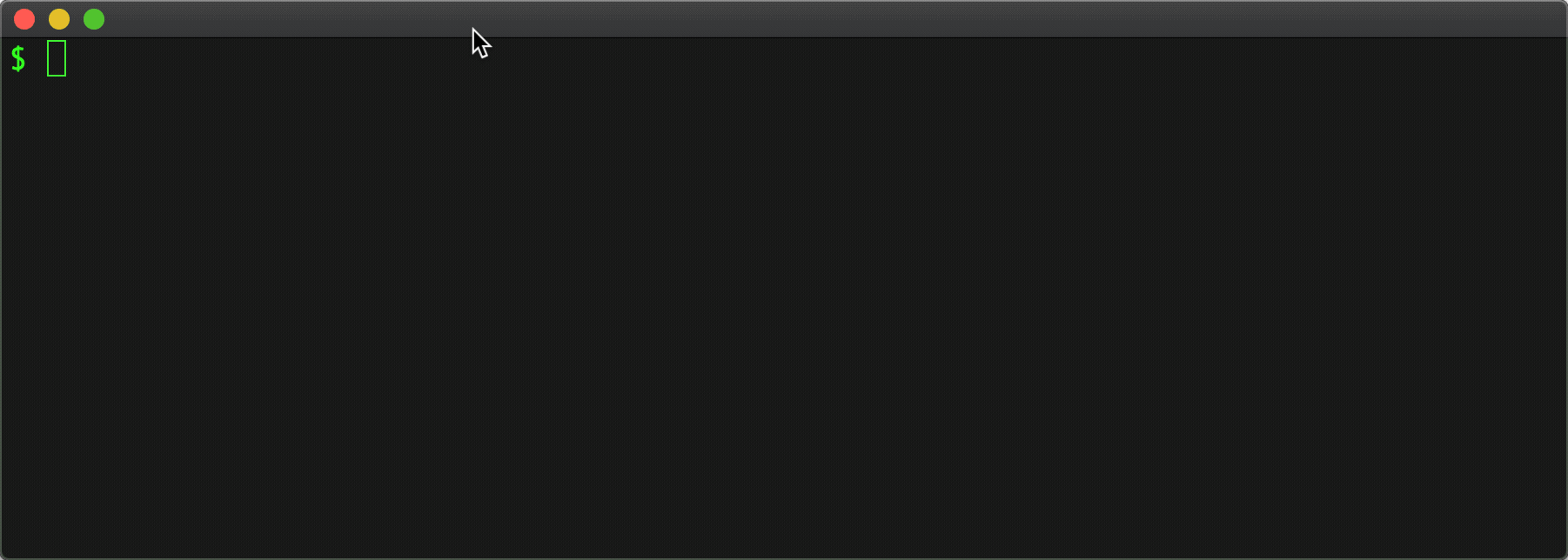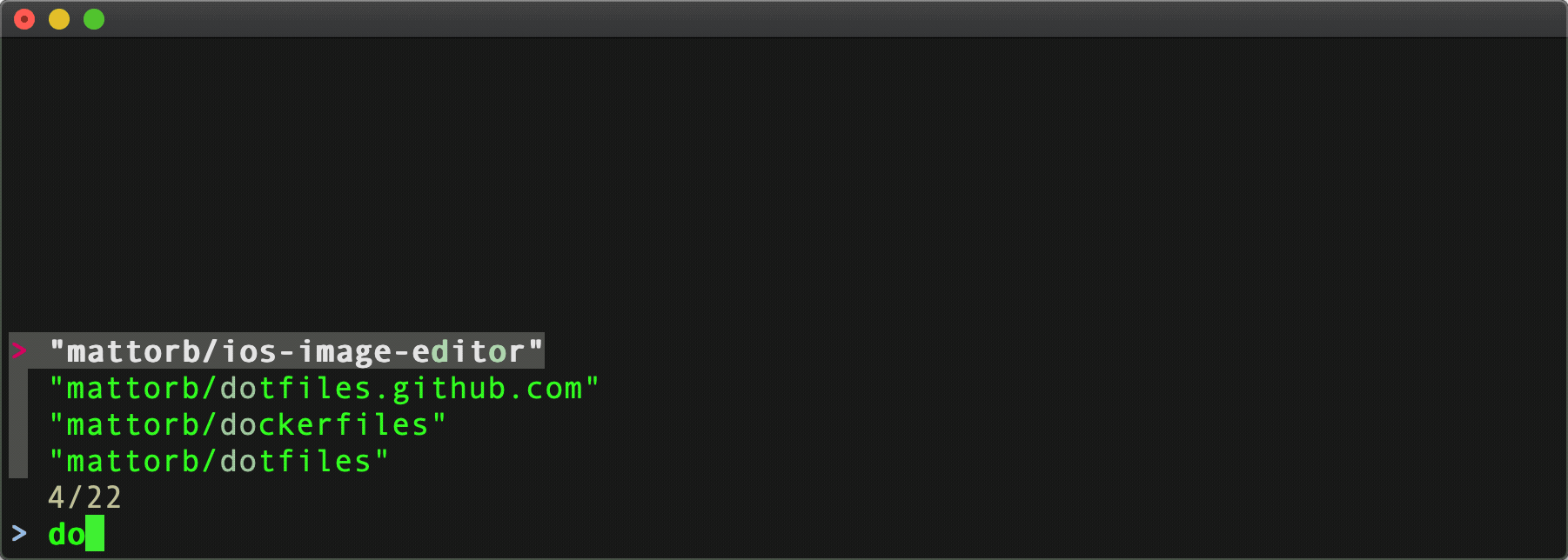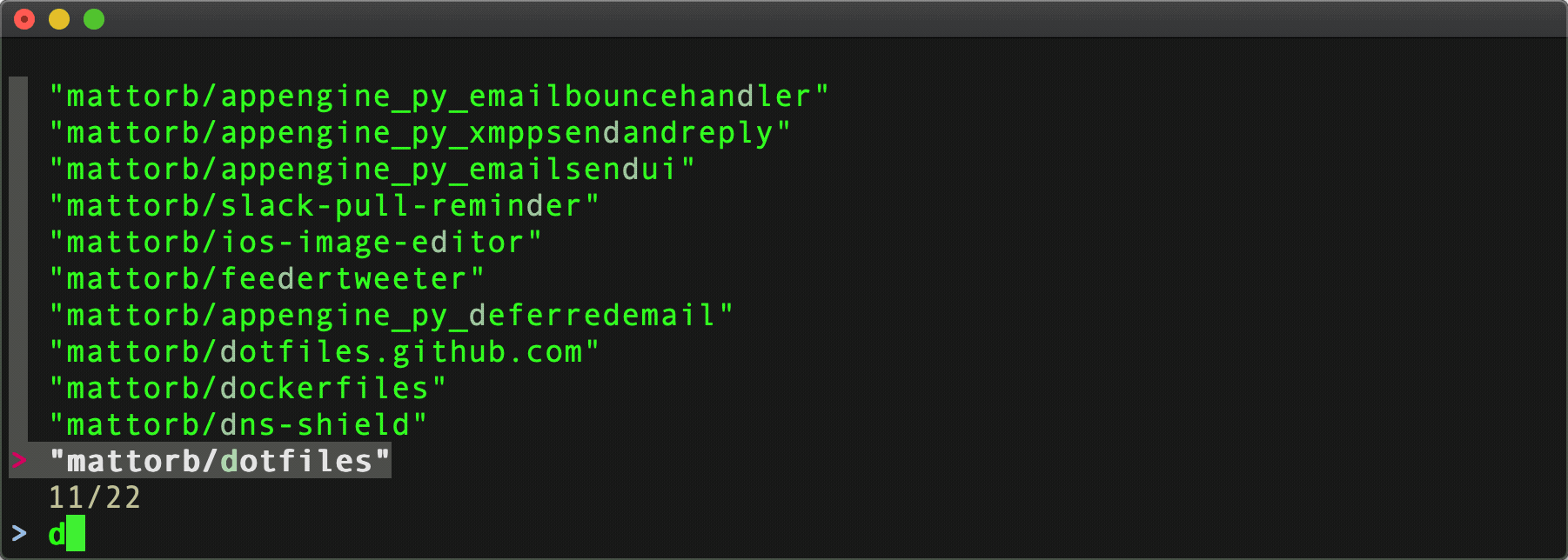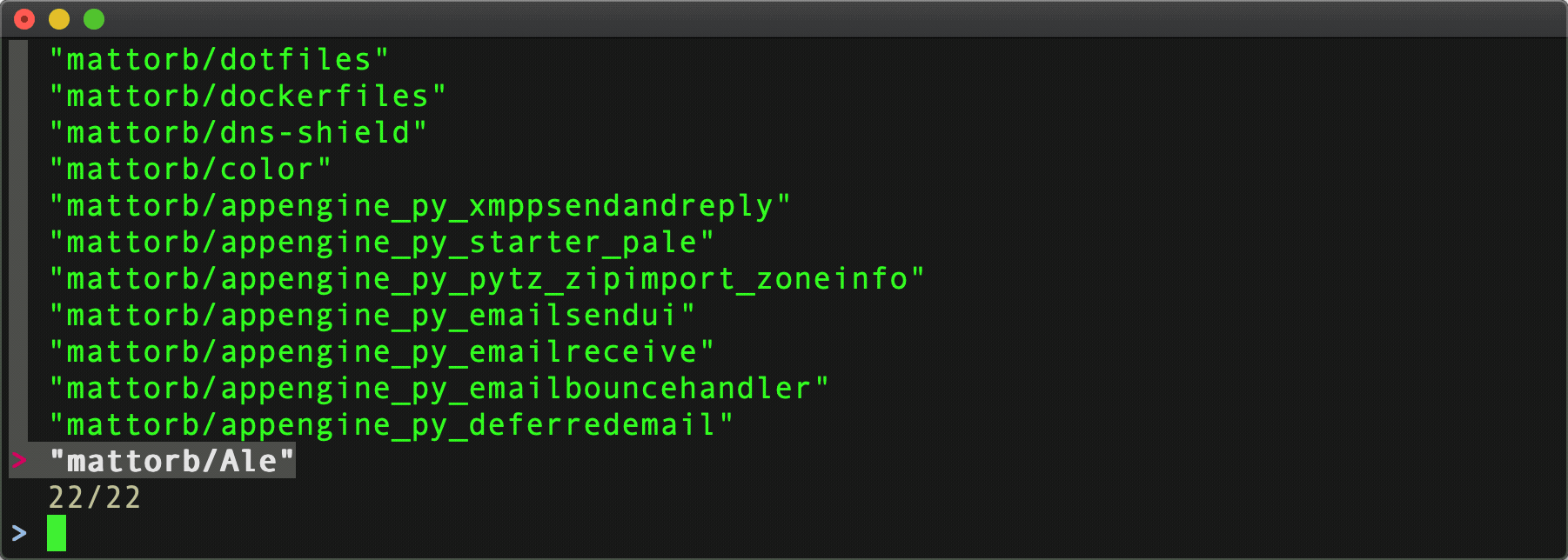
$ curl 'https://api.github.com/orgs/github/repos' | jq '.[].full_name' | fzf
Results:
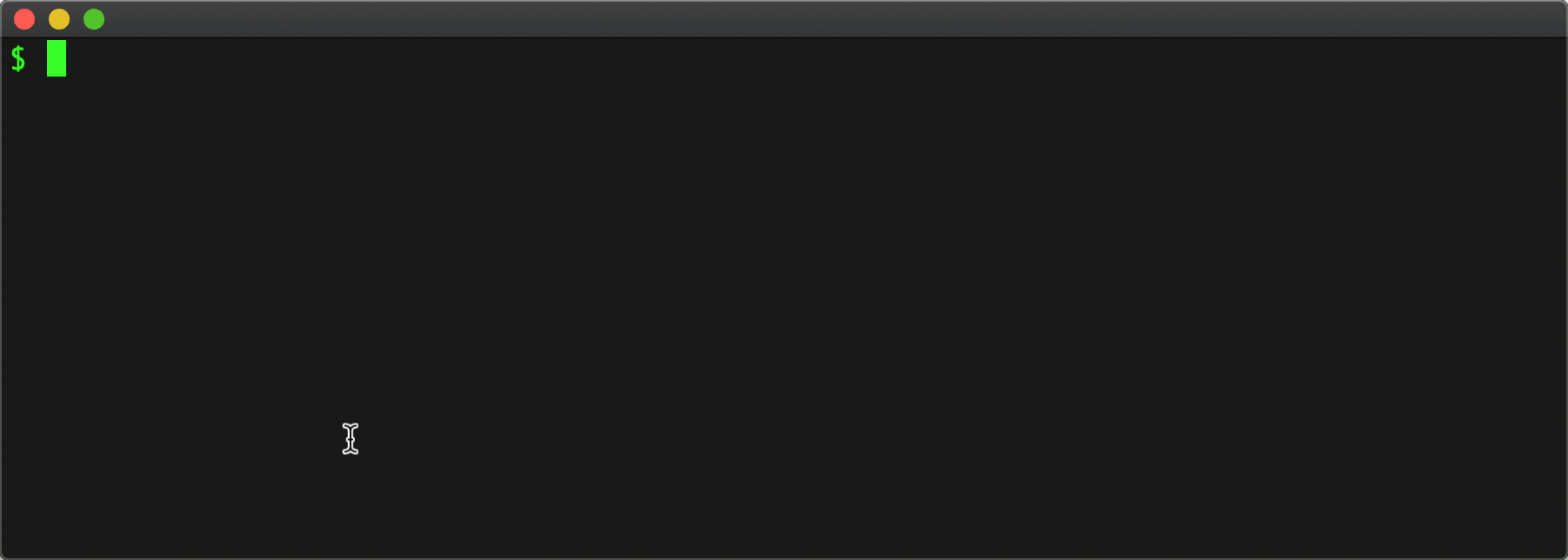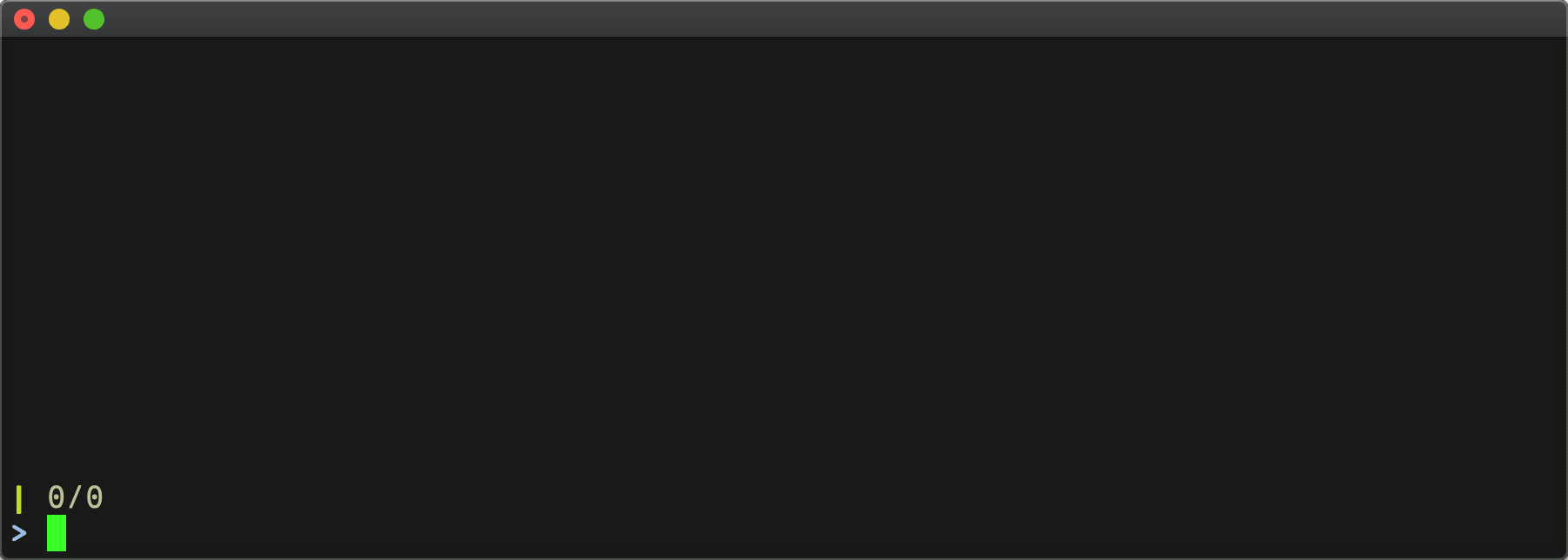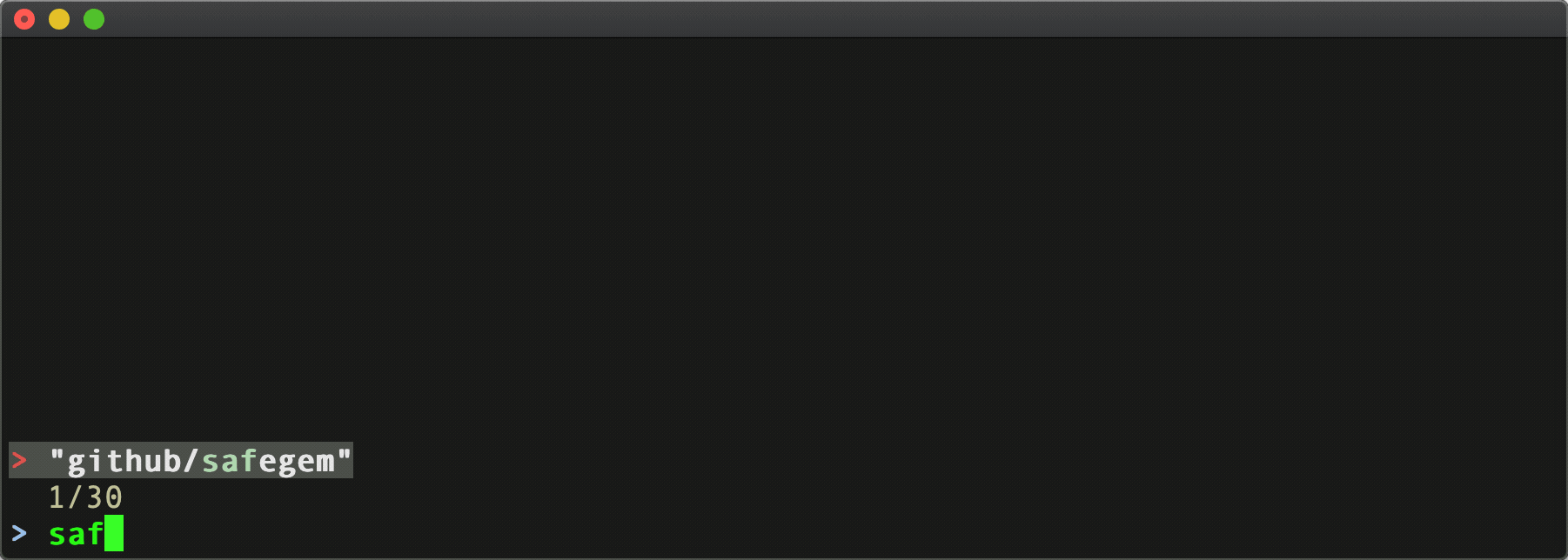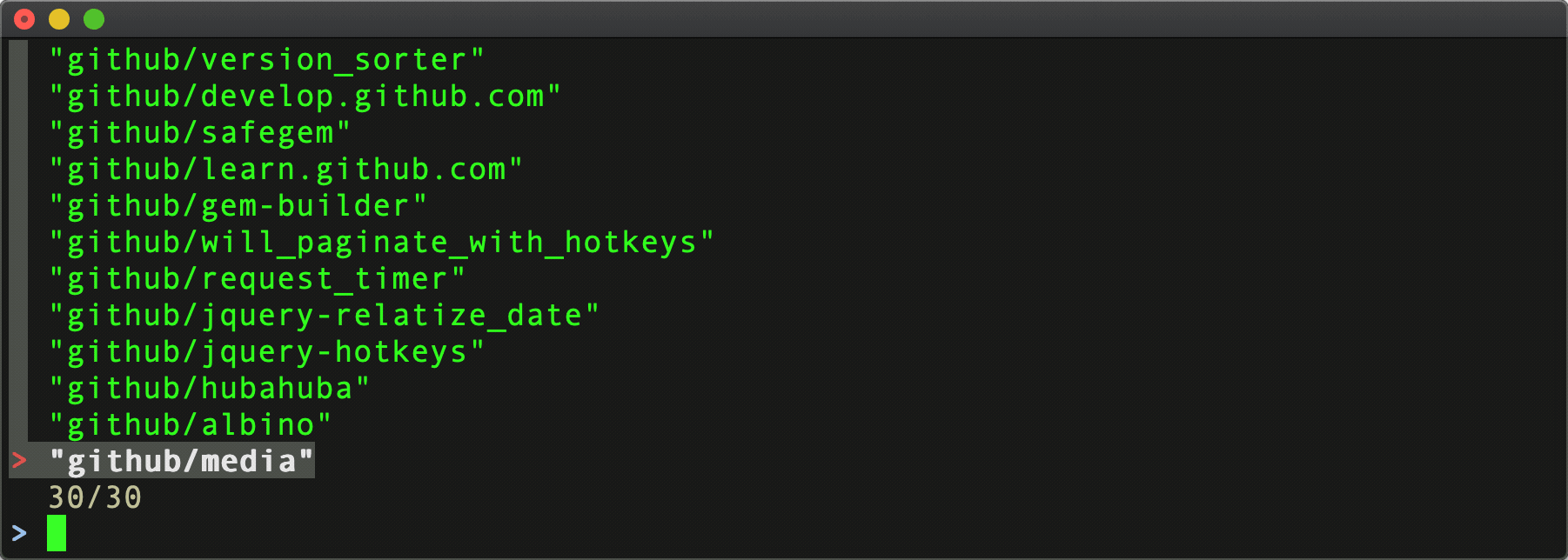
Hmm only 30 results.
Something doesn't seem right about that.
The Github organization has more public repo's than that. It turns out the Github API has pagination parameters. Adding per_page and page to the request yields more results.
Command:
$ curl 'https://api.github.com/orgs/github/repos?per_page=100&page=1' | jq '.[].full_name' | fzf
Results:
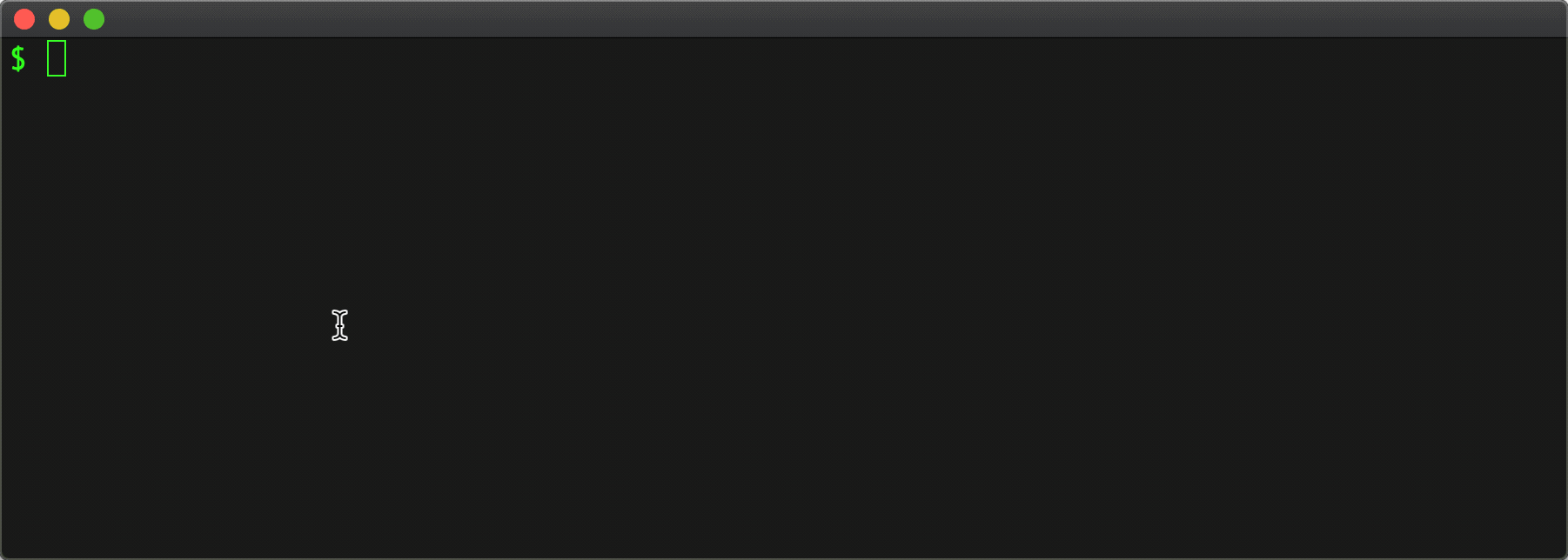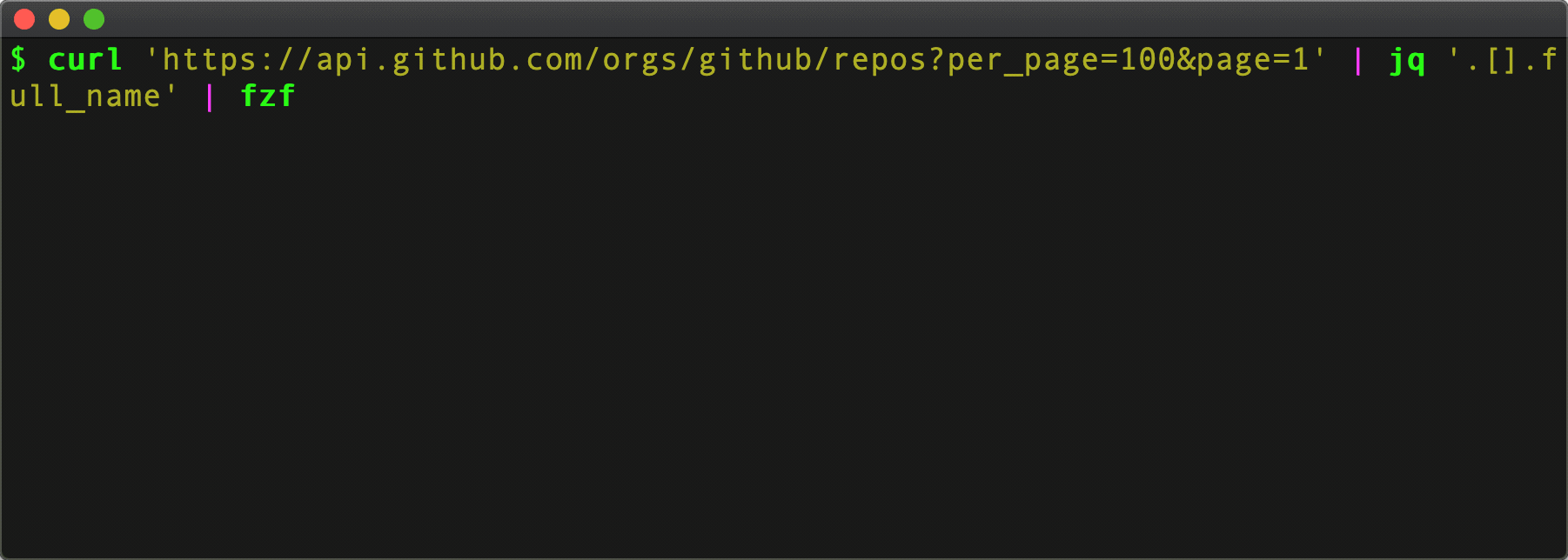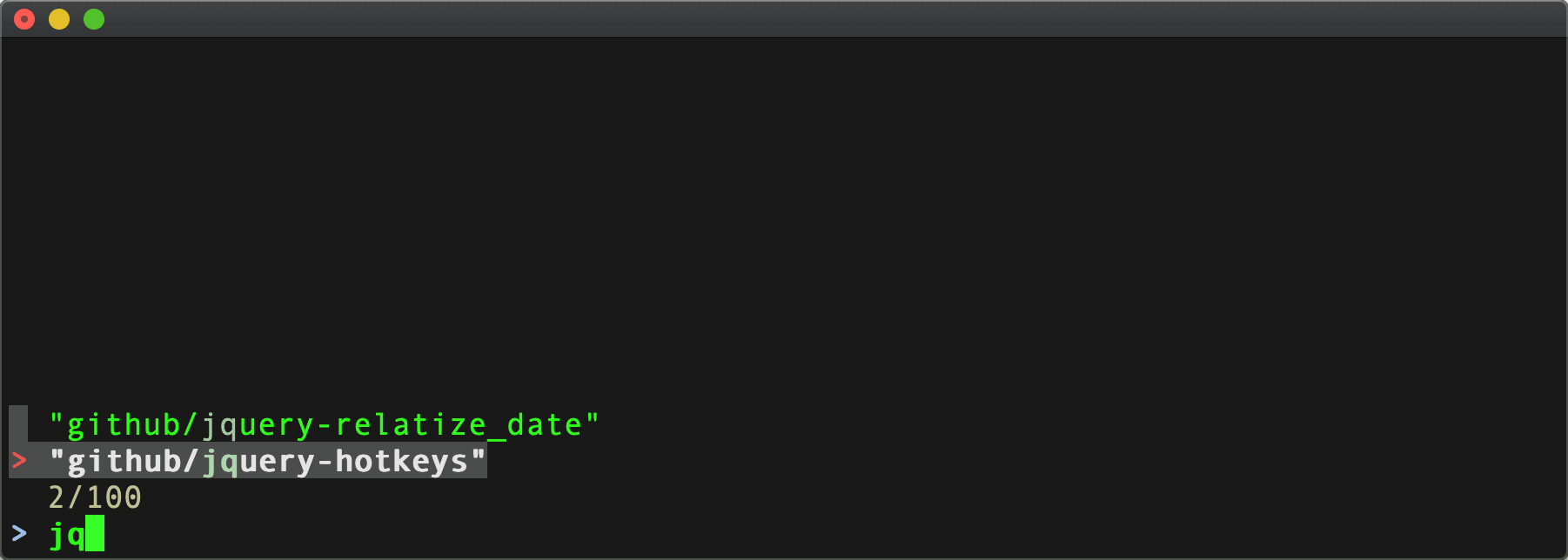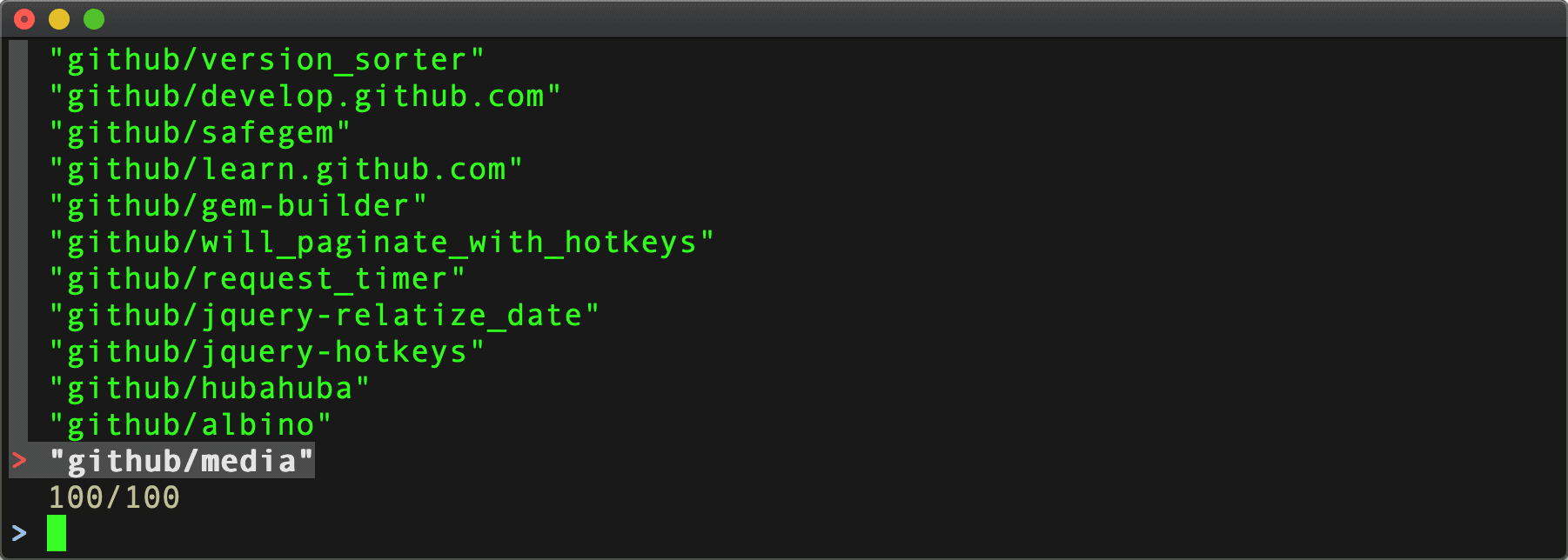
^ This gets us up to 100 results, but the github org has even more [public] repo's than that – 295 at current count. However, the API returns at maximum, 100 per page, so we're going to need to handle pagination to retrieve them all. Boo.
Version 1 - What are we doing?
Responsiveness
At this point, interacting with the user interface I already had in fzf, there was a noticeable pause between invoking the command and seeing 100 results to choose from suddenly pop into the fzf UI. I was curious if parsing json results from the Github API via jq was handling the entire response as a unit, and then only sending results at the end of that processing, affecting how responsive the fzf UI felt. Would it feel more responsive if the json coming back from the API could be parsed and streamed out, as it was streamed in, so that fzf was being fed the first of the choices to present, sooner?
It turns out jq has some streaming friendly options, and curl has a way to disable output buffering (-N), so stringing those together, we get:
$ curl -N 'https://api.github.com/orgs/github/repos?per_page=100&page=1' | jq --stream -r 'select(.[0][1] == "full_name") | .[1]' | fzf
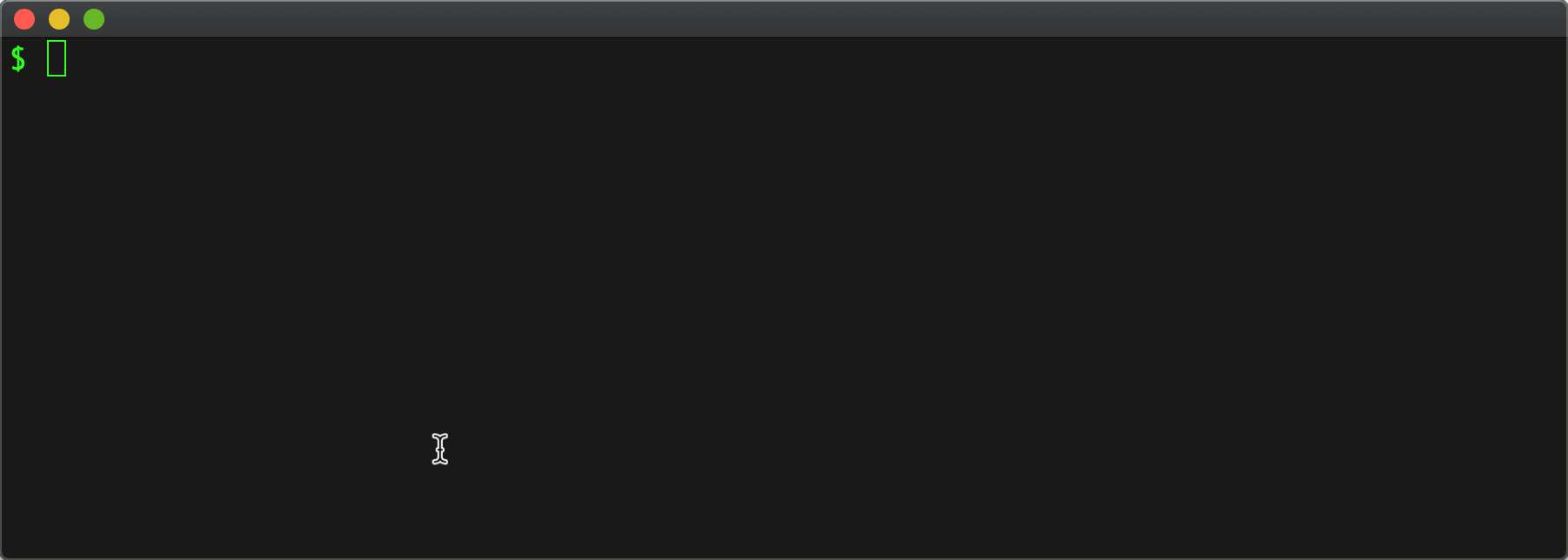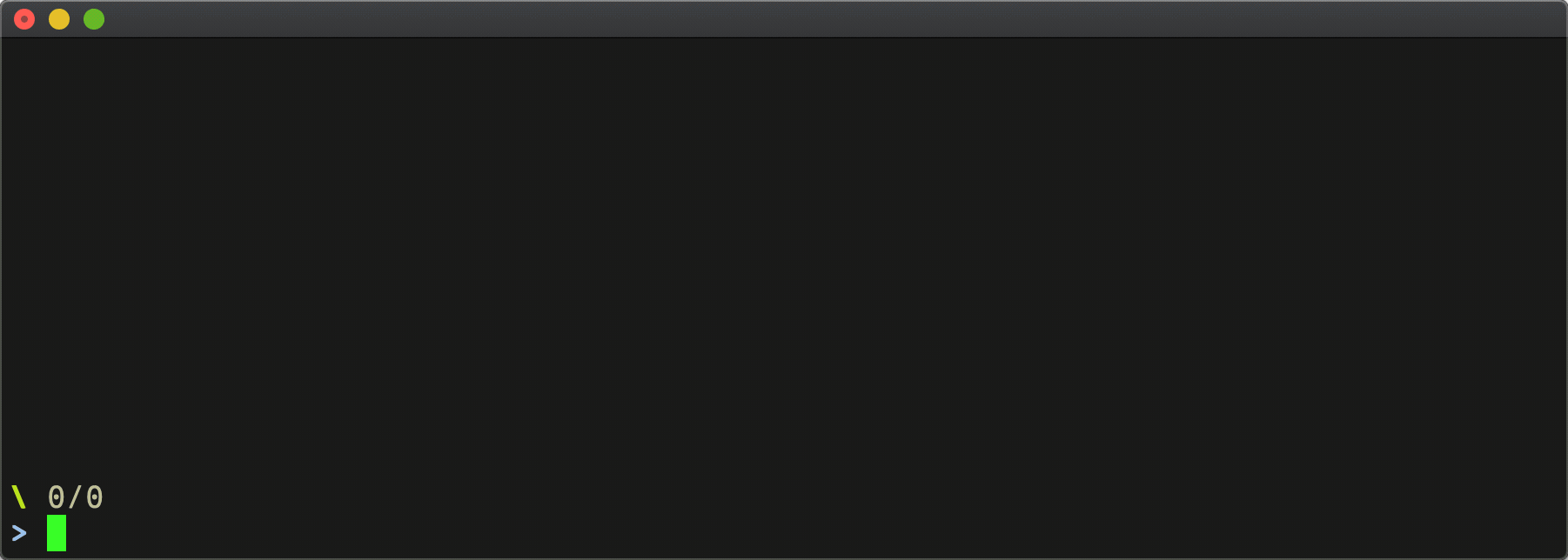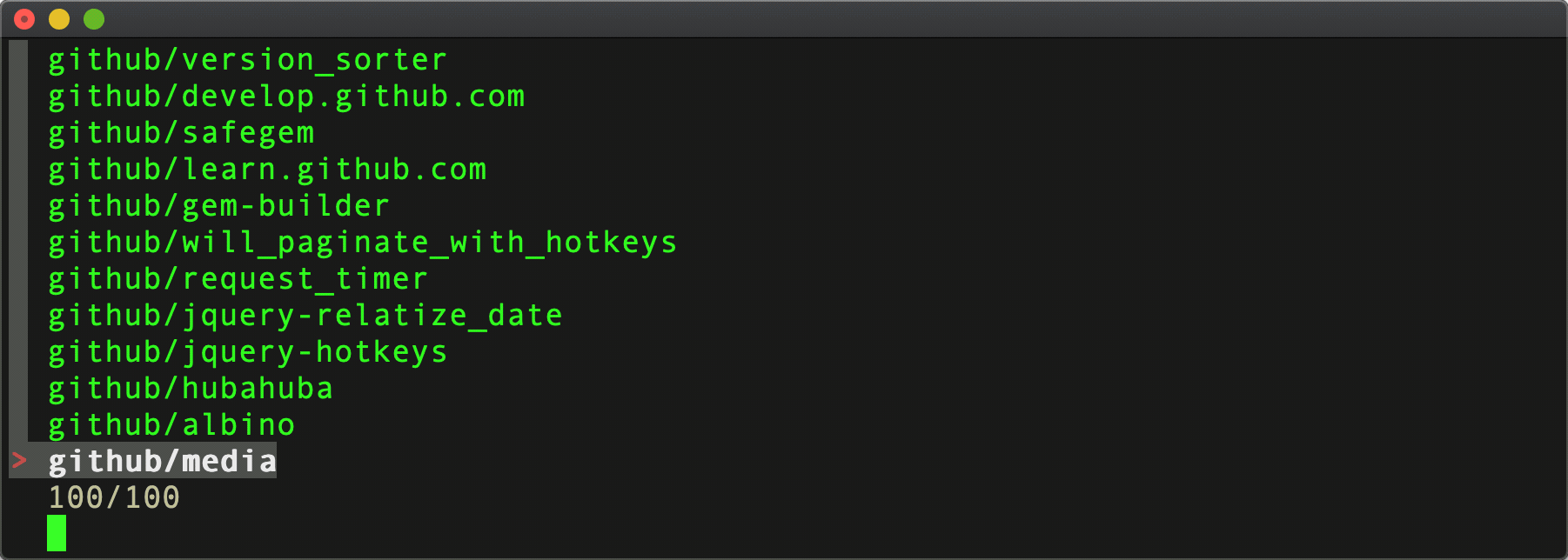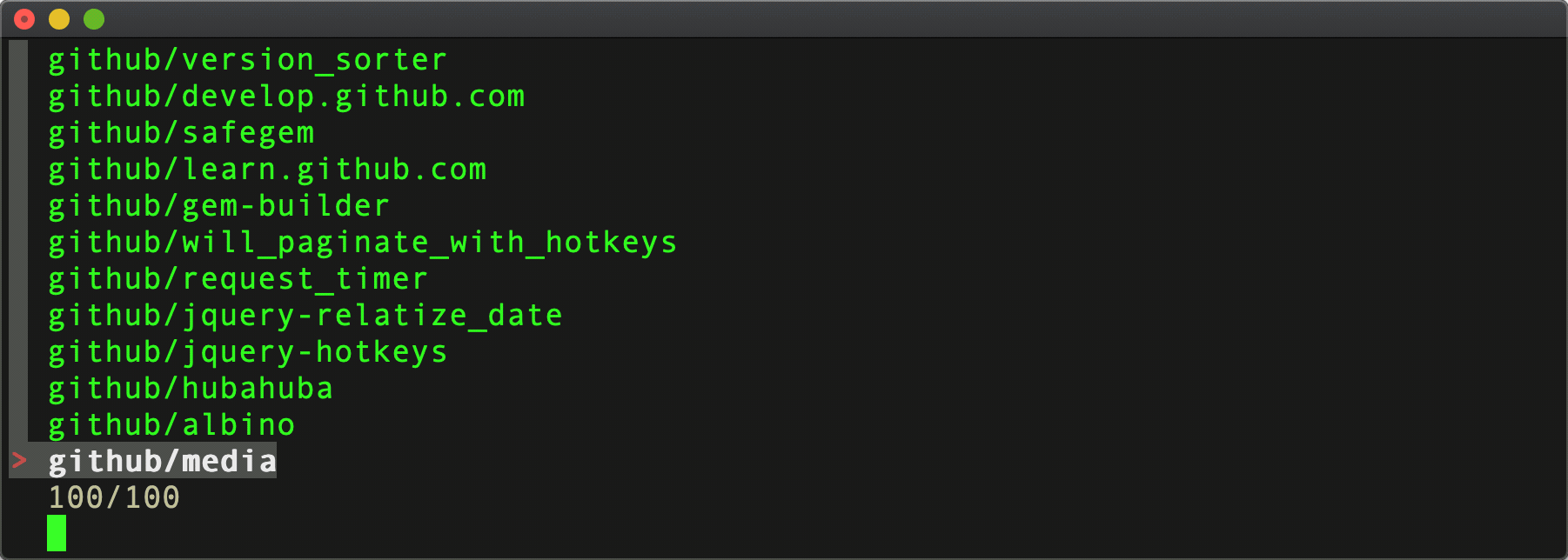
Sadly, it didn't feel more responsive at all! Notice the 1-2 second load time, and everything still pops in all at once...
I didn't dig deep on this, but some possibilities for the delay may be the overhead of getting the first connection to the API or the result data not being large enough to provide a visible performance benefit via the jq streaming mode, or lastly there is always the chance I'm doing it wrong with the command line options between jq and curl.
In any case, I decided to divert to figuring out pagination and handling private repo's, because without those I would definitely never use this thing.
Version 2 - Pagination, Private Repo's and Go. Oh my.
At this point I was becoming less and less excited about continuing to use shell scripting for every part of this, even if I were to do it in my preferred shell. I took a few quick passes at chaining more things together, but it was already headed in a direction of being a little too clever and quotes-inside-quotes-within-quotesy for my tastes. I like code I write to be easy to understand and modify long after I've been in the middle of it.
The part that felt especially inappropriate to start cobbling together in shell scripting was invoking the Github v3 API, parsing & filtering the JSON result with jq, retrieving subsequent pages of of data, and potentially wanting to parallelize that sequence more and weaving the results together into fzf friendly output.
I wanted to take a shot at building more of the logic in a language and with a runtime that would launch fast from the command line, handle pagination, concurrent requests, and parsing+streaming out the results as fast as possible to fzf. To retrieve all the needed data from the Github API a program should only need a personal access token and an organization name. If I could make something purpose built for that, focused on interacting with the Github API, and then pipe the results to fzf, I'd be in business.
Here's where Go, and the google go-github module come in.
I wrote a small program in Go to retrieve all of an organization's repositories that were visible using a given Personal Access Token.
Here's the important part of listrepo.go:
func listOrganizationRepos(client *github.Client, organization string) {
opt := &github.RepositoryListByOrgOptions{
ListOptions: github.ListOptions{PerPage: 100},
Type: "public",
}
for {
repos, resp, err := client.Repositories.ListByOrg(context.Background(), organization, opt)
if err != nil {
fmt.Println(err)
return
}
printRepos(repos)
if resp.NextPage == 0 {
break
}
opt.Page = resp.NextPage
}
}
After this, I also added retrieving the user's repositories for the authenticated user, as those are some I access commonly as well.
Command:
listrepo ( cat .git_patoken ) github | fzf
The first argument there is a file containing a personal access token. Use $(...) instead of (...) if coming from bash instead of fish.
Results:
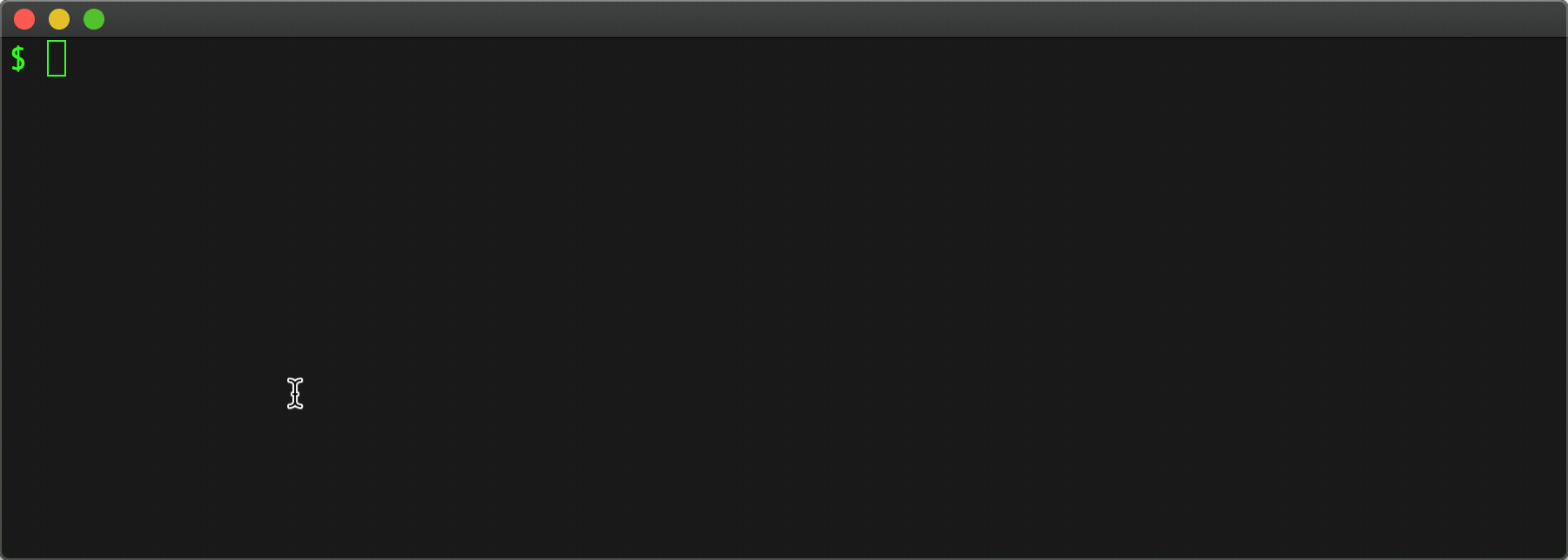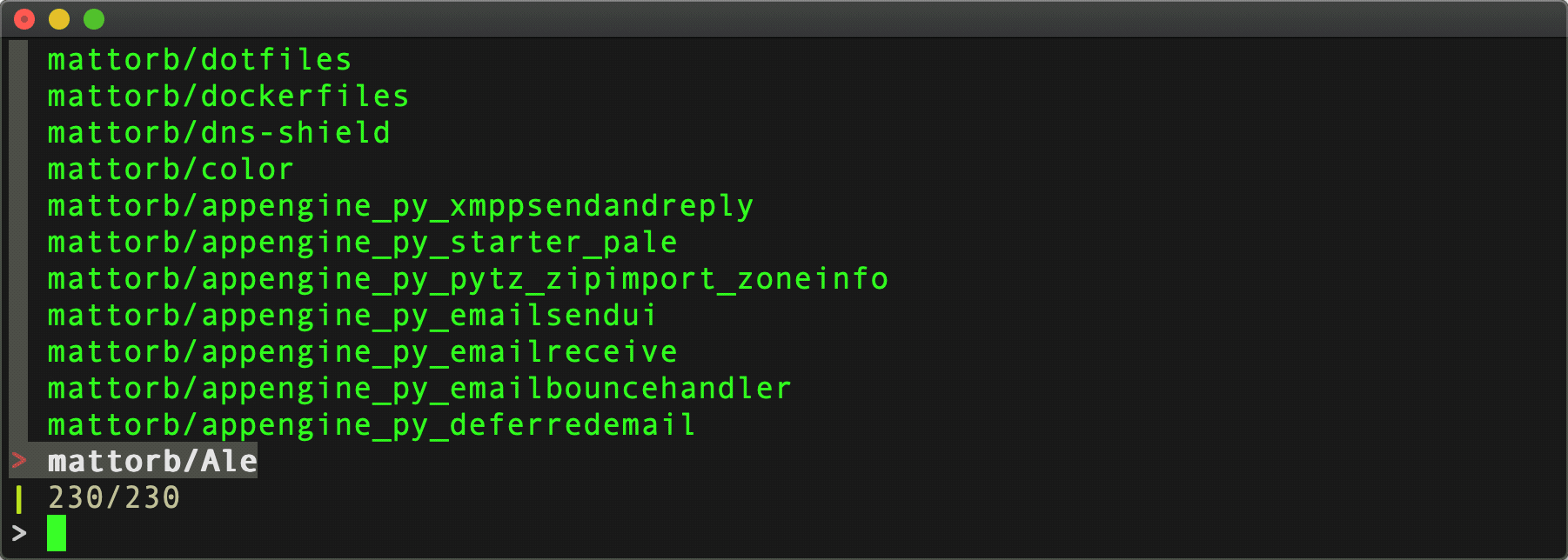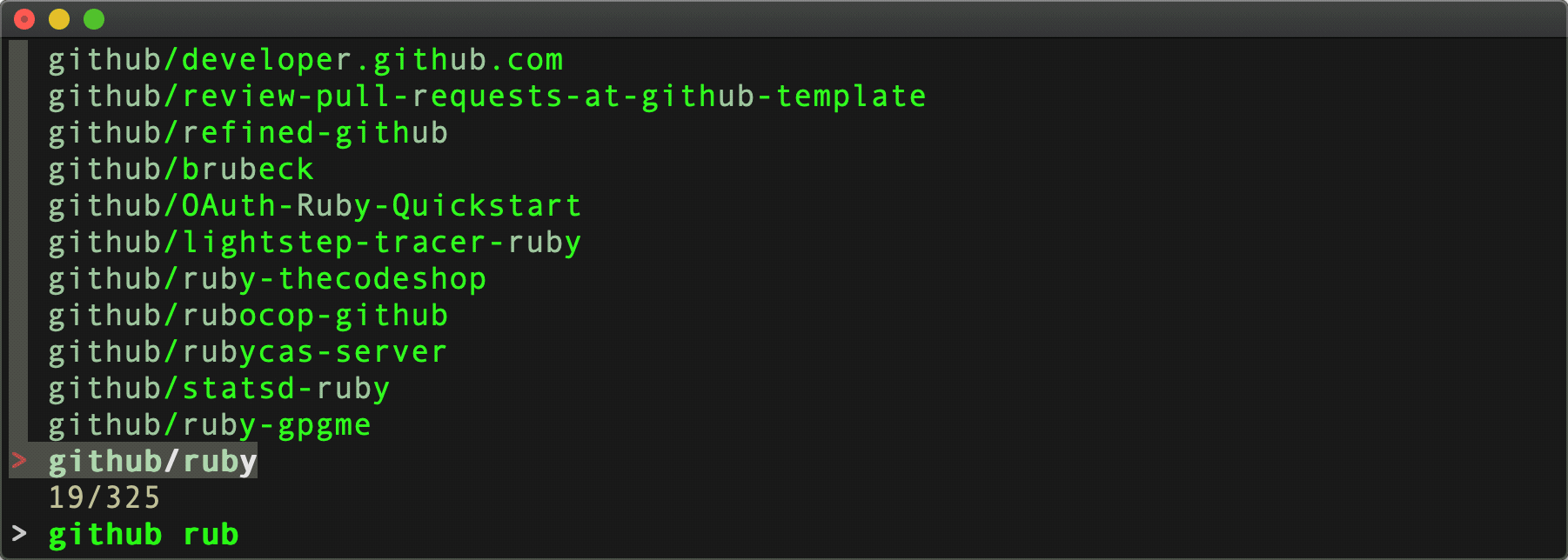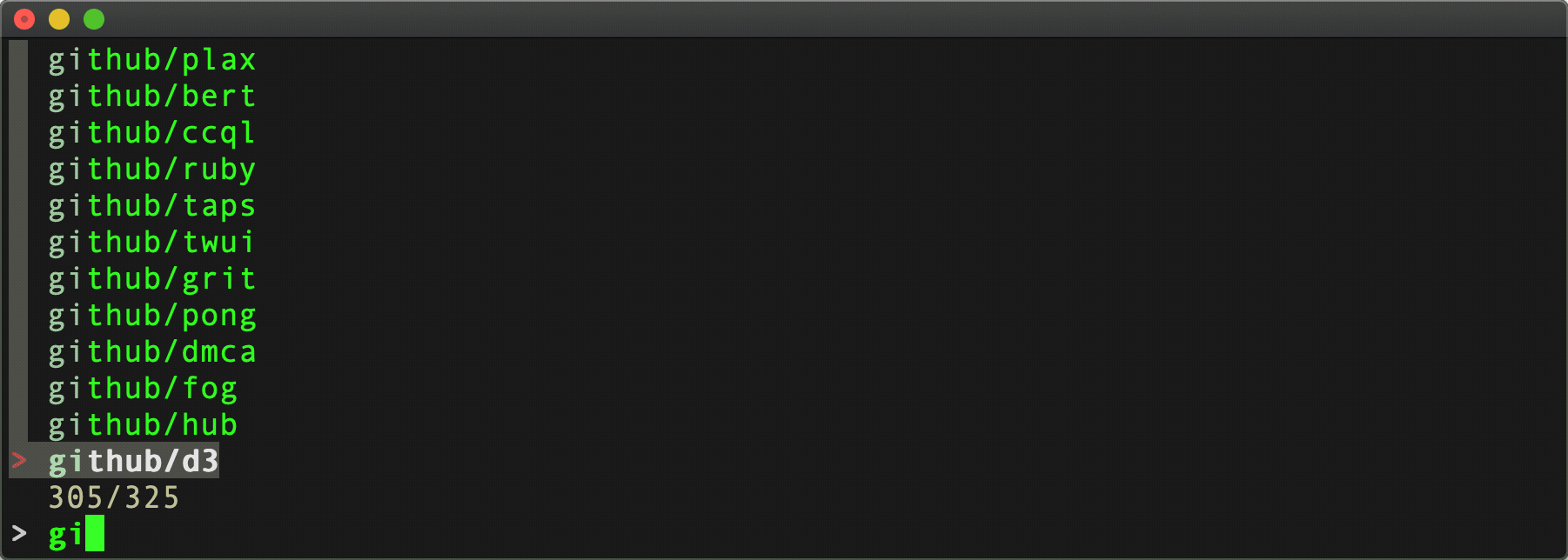
Paging: Handled. Authentication: Handled.
Number of API requests for repository data: 4. That's 1 request for 24 user repo's, then 3 [paged] requests for 295 github org repo's.
Listrepo w/ GitHub V3 API Performance
Since responsiveness is one of key success criteria, I wanted to minimize the total time spent retrieving the full list and make sure that any results were fed to stdout (and thus fzf) as soon as possible. To measure the total time for all requests to complete, which is our worst case of how long a user might have to wait if they are searching for repo that is on the last page of a series of API queries, I leveraged a tool called multitime.
multitime is a tool that runs a command repeatedly (-n [number of times]) and aggregates timing results to give a better idea of performance over multiple runs of a command.
$ cat v3.sh
#!/bin/bash
listrepo $(cat ./.git_patoken) github >/dev/null
$ multitime -q -n 10 "./v3.sh"
===> multitime results
1: -q ./v3.sh
Mean Std.Dev. Min Median Max
real 3.506 0.535 2.748 3.366 4.543
user 0.114 0.002 0.110 0.115 0.118
sys 0.026 0.001 0.024 0.026 0.027
$
3.5 seconds on average to retrieve details on 325 repositories. That's typically (68% of the time) 3-4 seconds considering 1 standard deviation.
Responsiveness
Even though all repositories are not retrieved until the full for 3-4 seconds have passed, fzf starts filling in the UI around 1-1.5 seconds after receiving the first page of results, and allows the user to start typing at any time to affect the displayed matches. As subsequent pages are retrieved from the GitHub API, the UI is updated and adjusted in real-time, so this interaction was already feeling ok for my needs. However, something was bugging me about this whole setup.
Version 3 - Github API v4 (GraphQL)
At this point, I began to re-evaluate my life choices. Well . . . at least my API choices. Looking at all the data I was not using in the Github V3 API responses, I began to wonder: Shouldn't there be a way to retrieve just what I need (the repo name), without bringing along all the other repository metadata? If only the API wasn't so rigid . . . If so, might that laser focused query also be more performant? Further, if I only need that tiny piece of [name] data from each repo, shouldn't I be able to avoid multiple 'paged' requests and all the network overhead that comes with them?
Side note: When I initially googled 'Github API', the top result was the Github API v3 Developer Guide. However, this is not the latest version of API. Github has a v4 API that is GraphQL based and it is awesome.
Thus, my excuse to explore GraphQL came into this world.
To write the GraphQL query for the data, I leveraged the very handy Github v4 API explorer and came up with this for the org query.
Query (GraphQL):
{
organization(login: "github") {
repositories(first: 100) {
nodes {
nameWithOwner
}
pageInfo {
endCursor
startCursor
hasNextPage
}
}
}
}
Results:
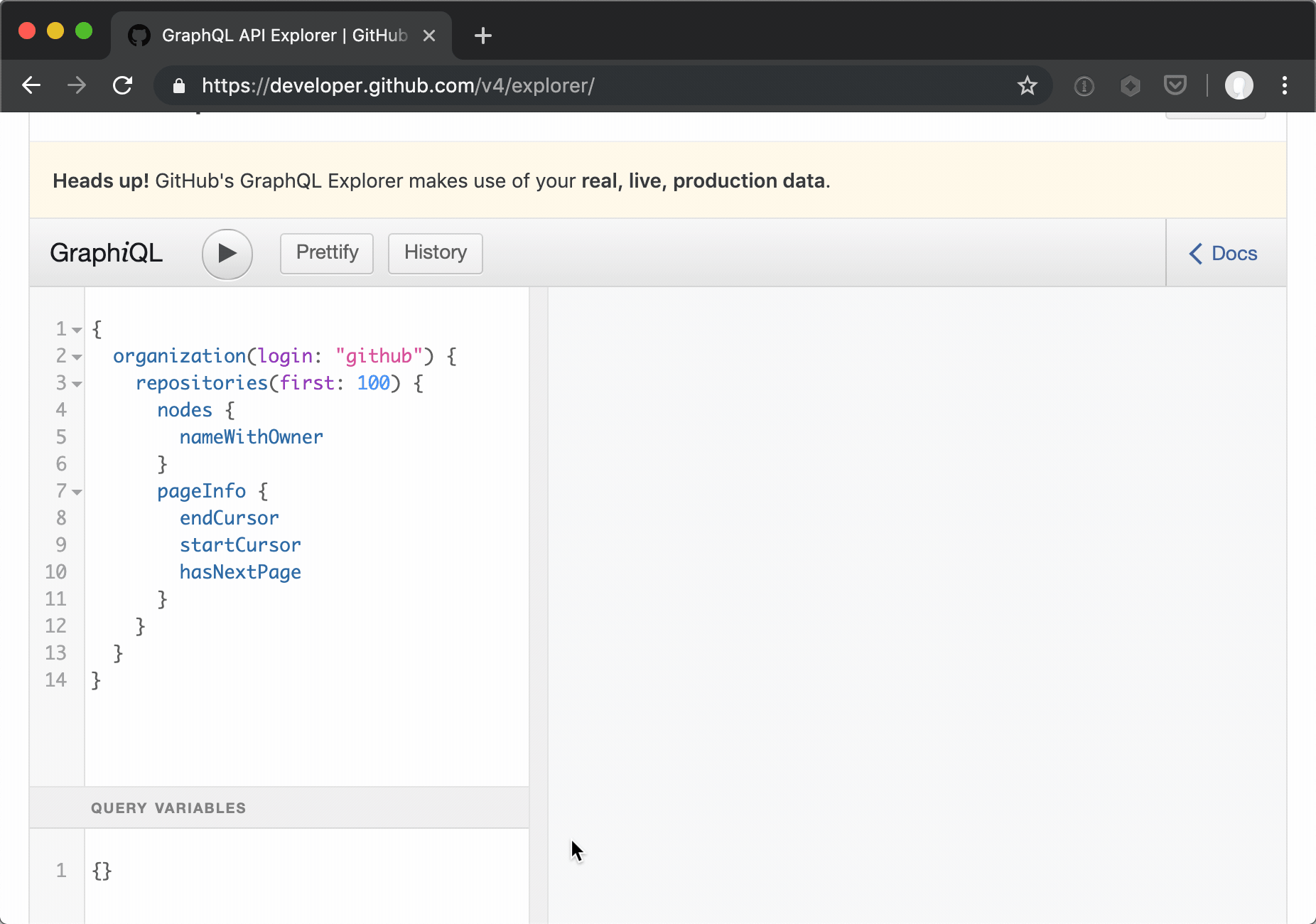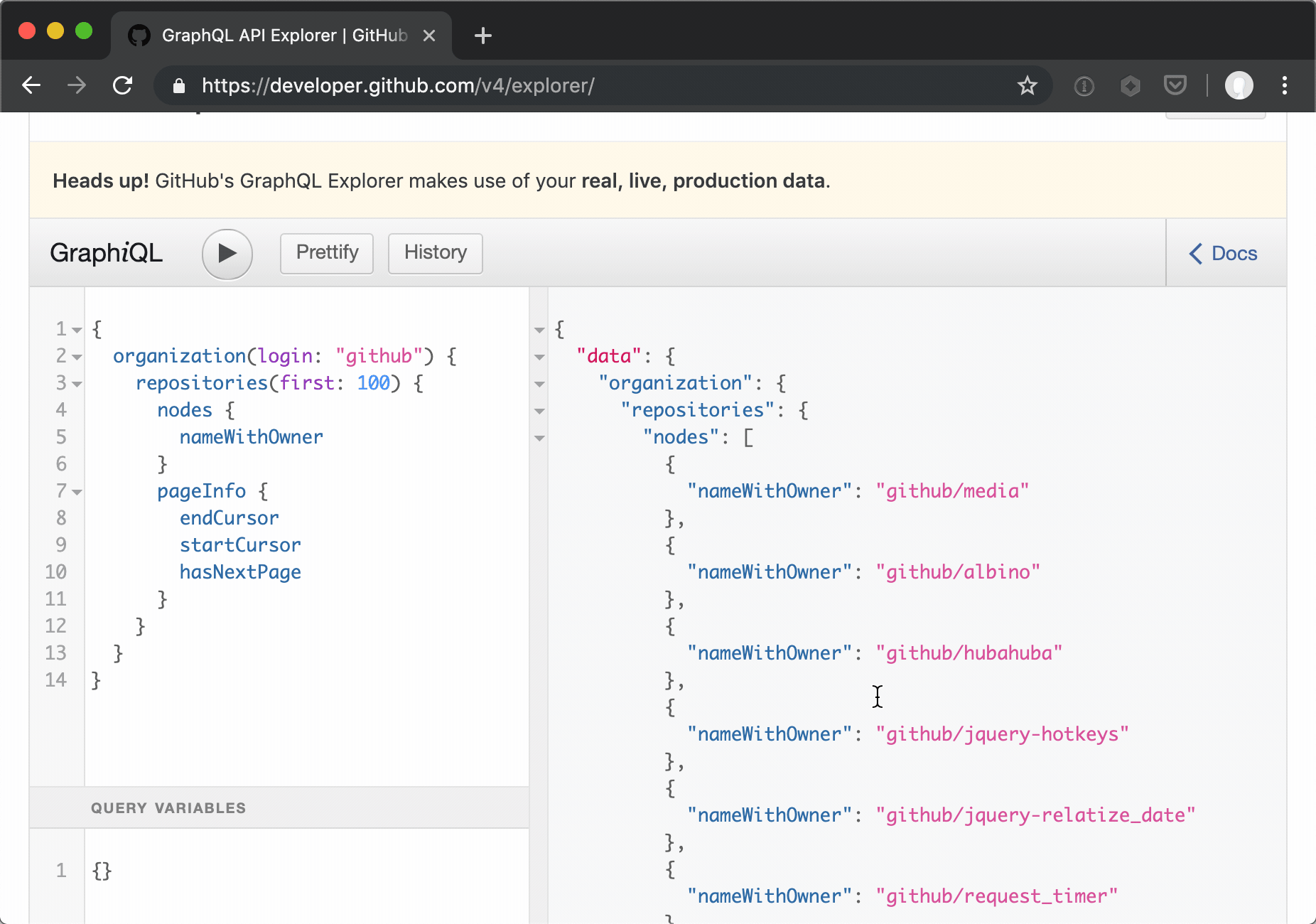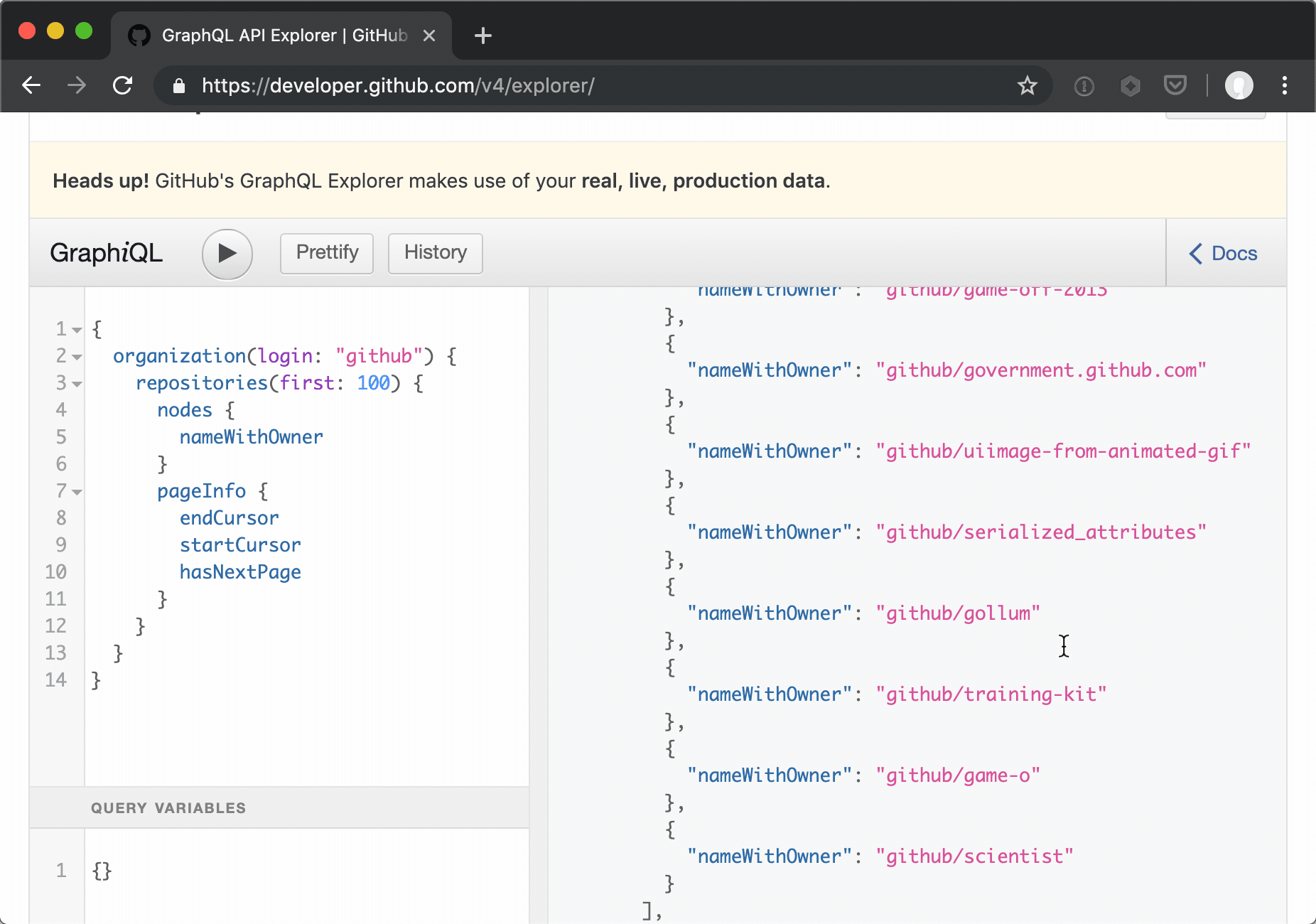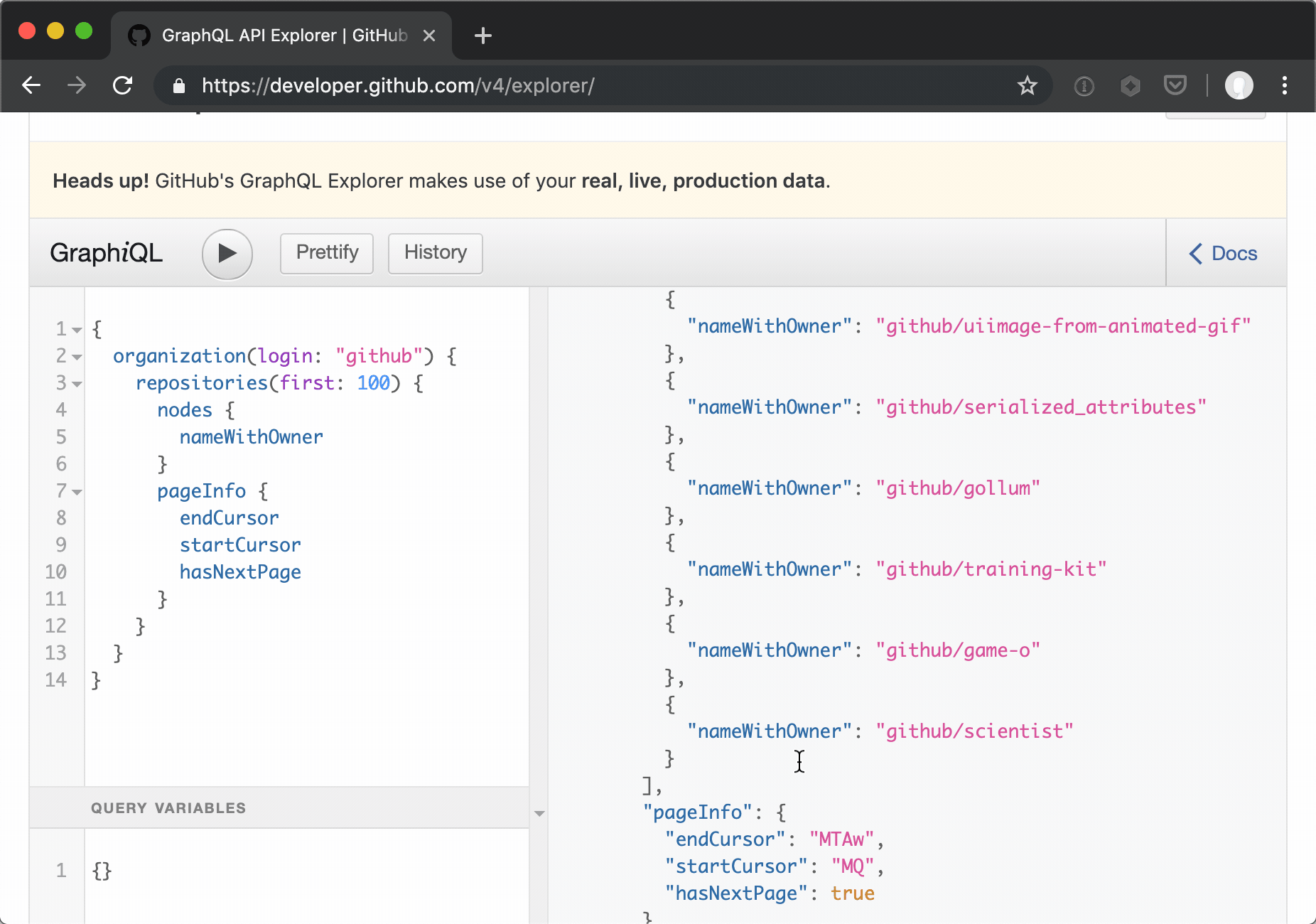
Paging is a bit different in Github's implementation of a GraphQL API (vs their v3 API), providing named cursors for subsequent requests.
Here's where things get a bit crazy
As part of the data I'm fetching, I was hoping to get a full list of org repo's -AND- the user's repo's, so type-ahead search could be done across the union of those results. In the REST API, those are distinct queries against different endpoints. With GraphQL though, multiple queries, even against different types of objects, can be thrown at the single GraphQL endpoint in a bundled request. So, I added the user query in there too. Thus a single request sends two queries to the Github V4 API at the same time, and the response for both gets bundled together and sent back in one package. waaaaaaaat? Additionally, the subsequent requests to navigate paging through each of those distinct queries can bundle as well, reducing total network requests.
Noice!
Next I wrote out the curl command to execute this against the Github v4 API . . . just to make sure I understood what was going on with GraphQL requests and responses. Building something without the GUI/wizard/sdk is a good way to make sure you understand the basics, before adding layers on top.
Points of interest from using the GraphQL GitHub API v4:
- Pagination: Still limited to 100 per page and we still have to page through results, due to the Github v4 API design. I really wish requesting a couple of hundred private repository 'name' values could be done in one shot, but I'm not seeing it in the v4 API at this moment. Github doesn't appear to support 'plurals', instead favoring the complete connection model in their GraphQL API pagination implementation.
- Fewer requests: We were able to bundle distinct (user and org) repository queries into fewer requests total requests. Presumably if I ever added another org in the query, that would also benefit directly from the reduction of network requests, including while paging through all those distinct result sets in parallel with bundled network requests.
- Less Data transmitted in result: We retrieve only the single field of data we need so there is less to send across the wire and hopefully a tighter, more performant query or cache hit on the backend.
Github GraphQL w/Go
Next up, I identified a Go module for Github v4 API which offered a strongly typed way to define GraphQL requests/responses and built a new listRepo_gql program to leverage that.
Listrepo w/ GitHub V4 API Performance
$ cat v4.sh
#!/bin/bash
listrepo_gql $(cat ./.git_patoken) github >/dev/null
$ multitime -q -n 10 "./v4.sh"
===> multitime results
1: -q ./v4.sh
Mean Std.Dev. Min Median Max
real 1.557 0.383 1.129 1.440 2.298
user 0.055 0.001 0.052 0.054 0.057
sys 0.023 0.001 0.022 0.023 0.025
$
An average of 1.5 seconds, typically (68%) within 1.2 to 1.9 seconds – 1 standard deviation. For retrieving our test set of repo's, this appears to be a 57% increase in performance over the non-GraphQL Github API v3 equivalent of our Go program.
Responsiveness
There's still a noticeable pause on the first request (1 second), but the pagination seems to go much faster. Perhaps due to the named cursor being used in the API request for subsequent paging which might be hitting a cache?
In any case, 1.5 seconds to retrieve a couple hundred repo's via an API, streamed into FZF where I can start typing immediately? I'LL TAKE IT!
Putting it all together
Now that we have a purpose built Go program to fetch a list Github repo's, handling paging, authentication, parsing, and [page based] streaming out the results, we have the perfect thing to feed data to fzf.
In a fish function, we kick off listrepo_gql with a Github Personal Access Token and Organization name, streaming the retrieved user and organization repository names to fzf, where the user types to match against the choices and then selects one.
When the user picks a choice, we can trigger cloning the repo . . .
Sample [fish] function partial, named fclone
function fclone
listrepo_gql (cat $HOME/.github_patoken) github | fzf | read -l repo
if test -n "$repo"
echo "Cloning '$repo' from Github"
git clone "https://github.com/$repo.git"
end
end
Results
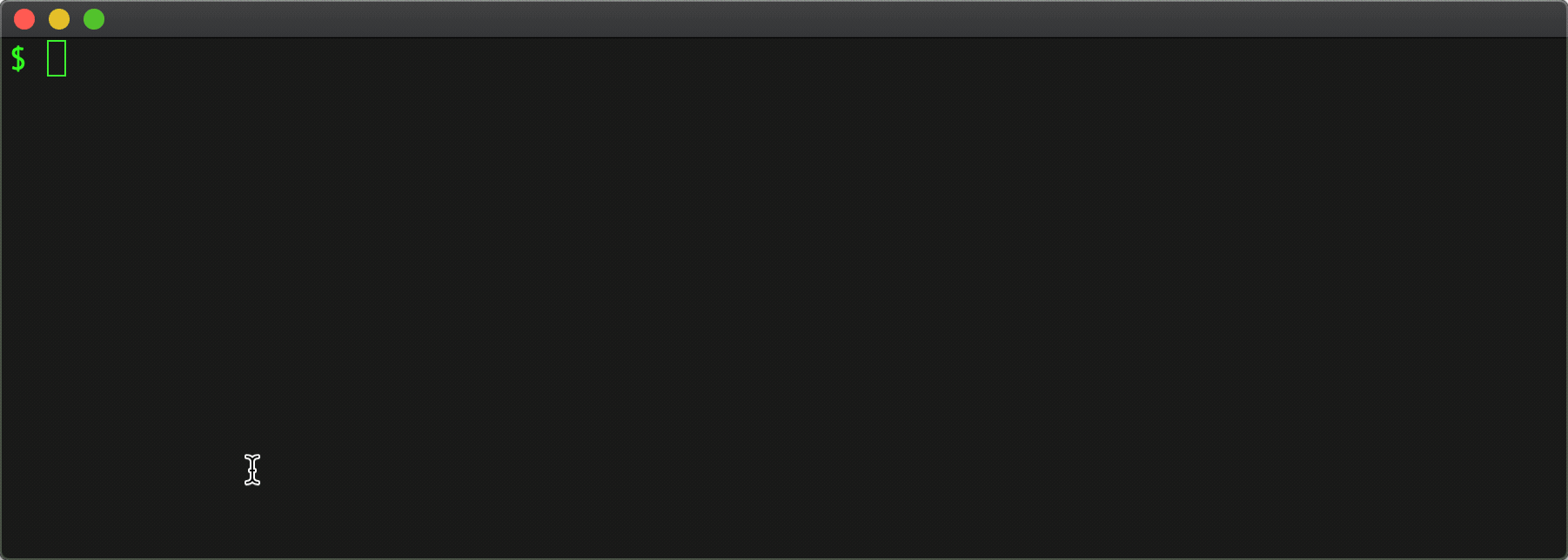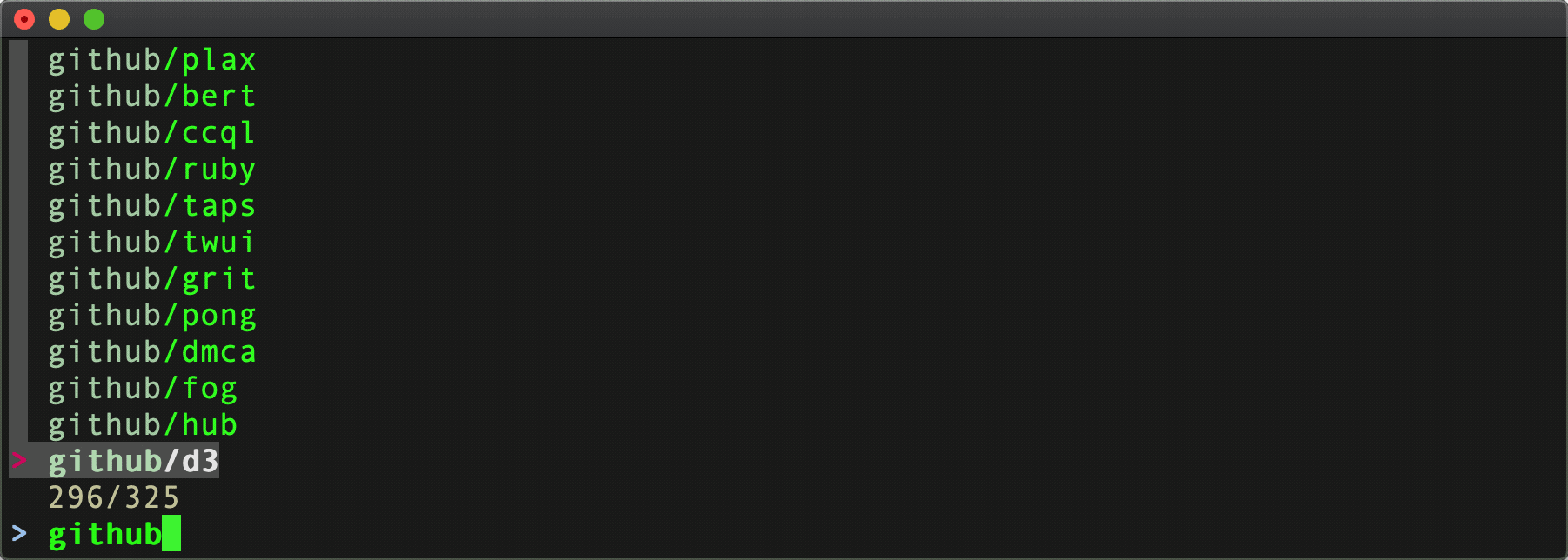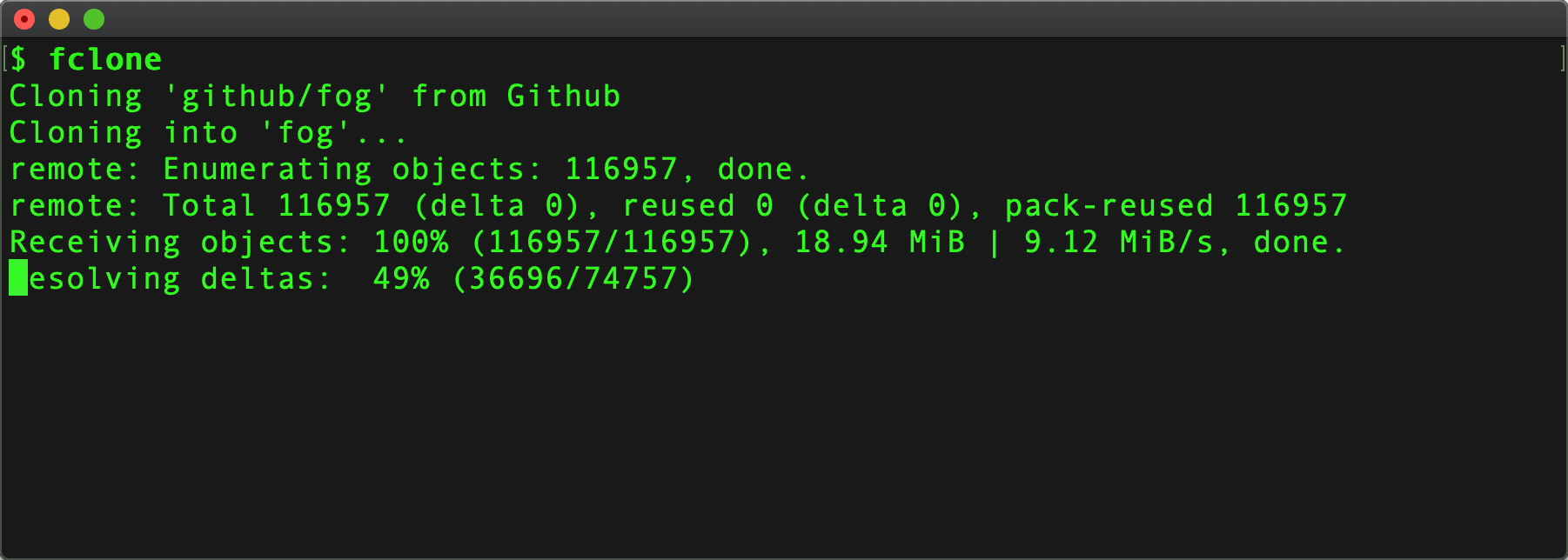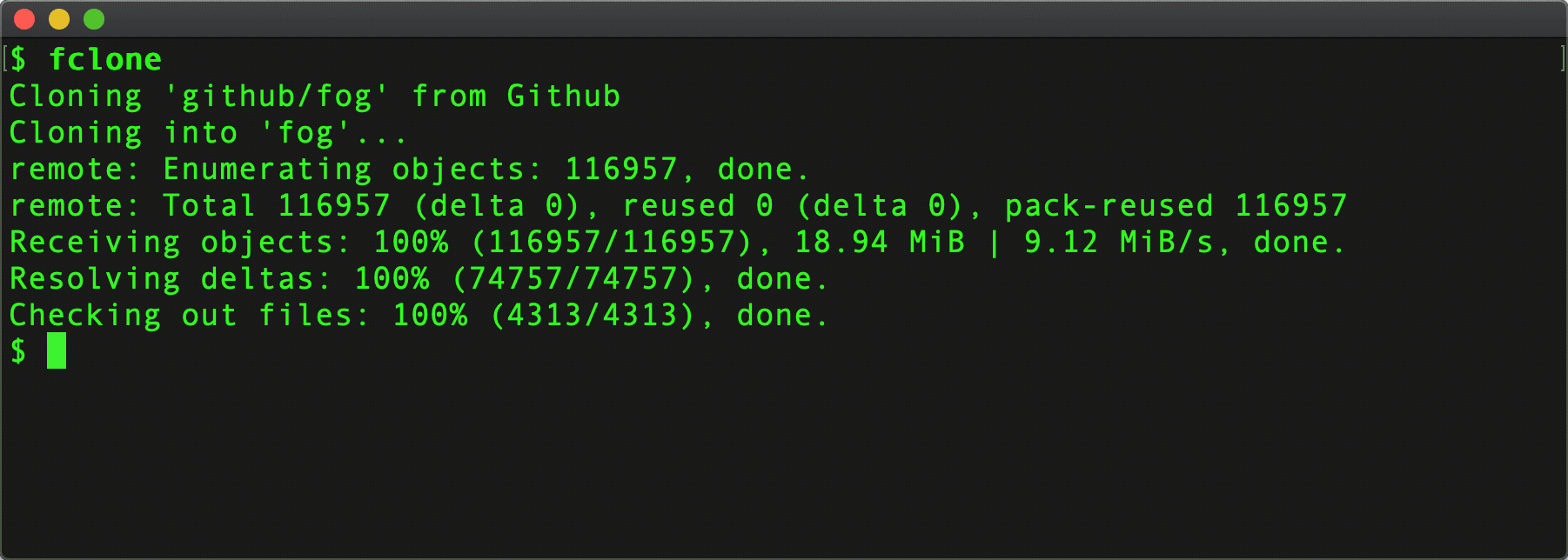
. . . or . . .
We can pop into a part of the Github Web UI for that repository using hub browse
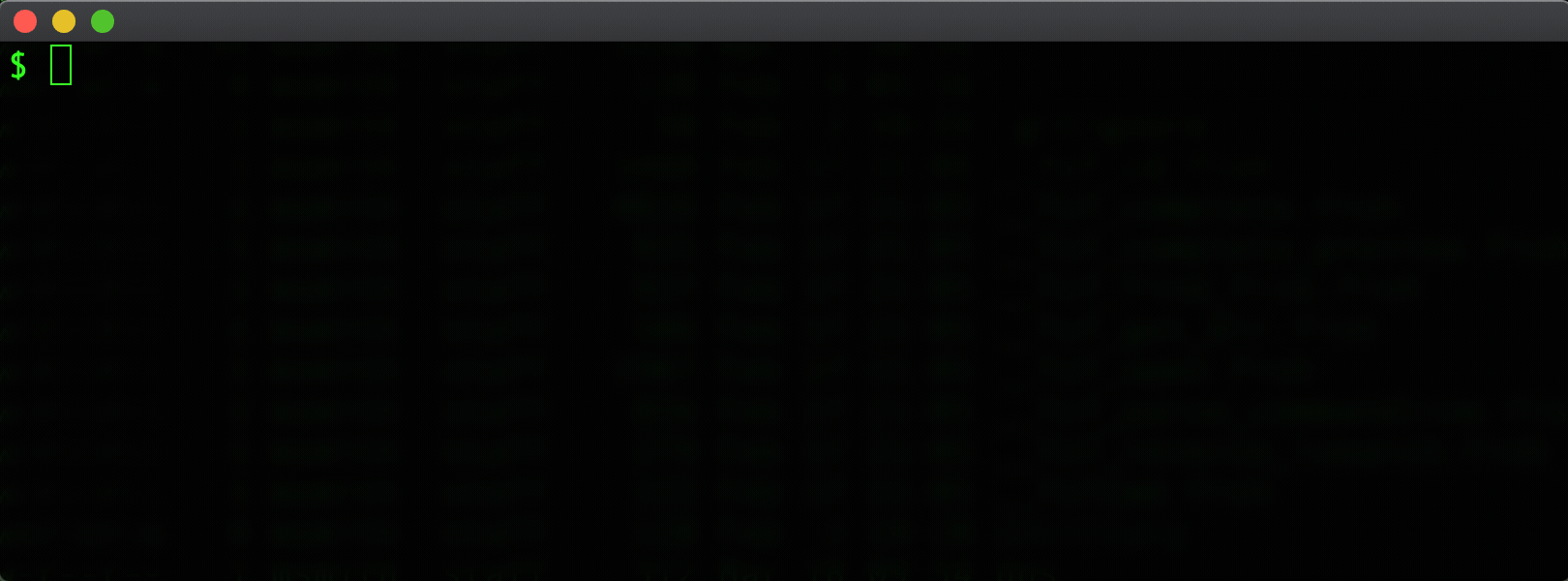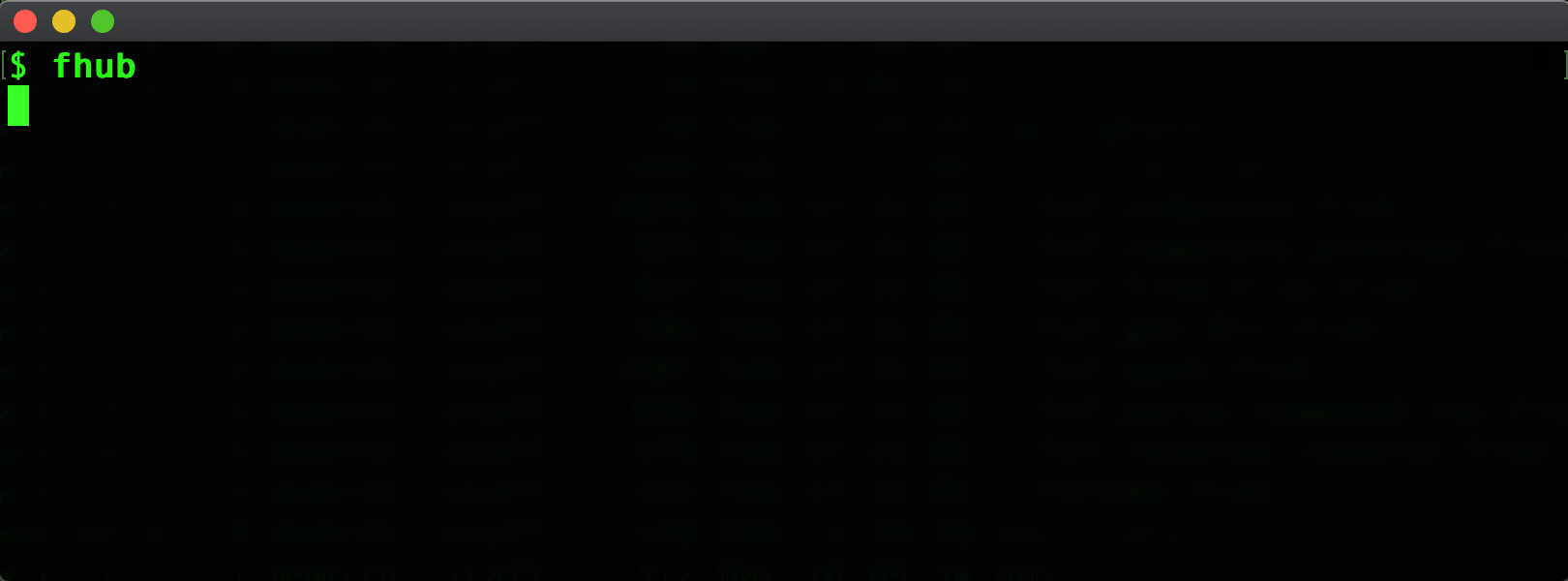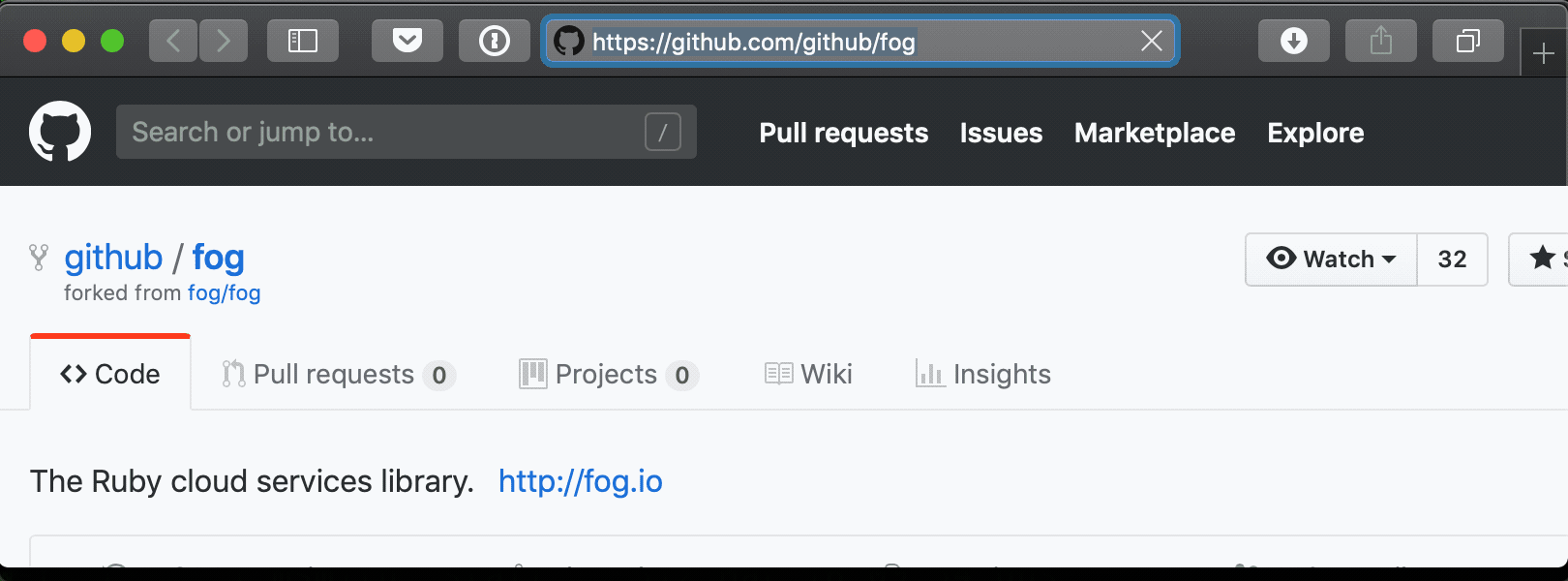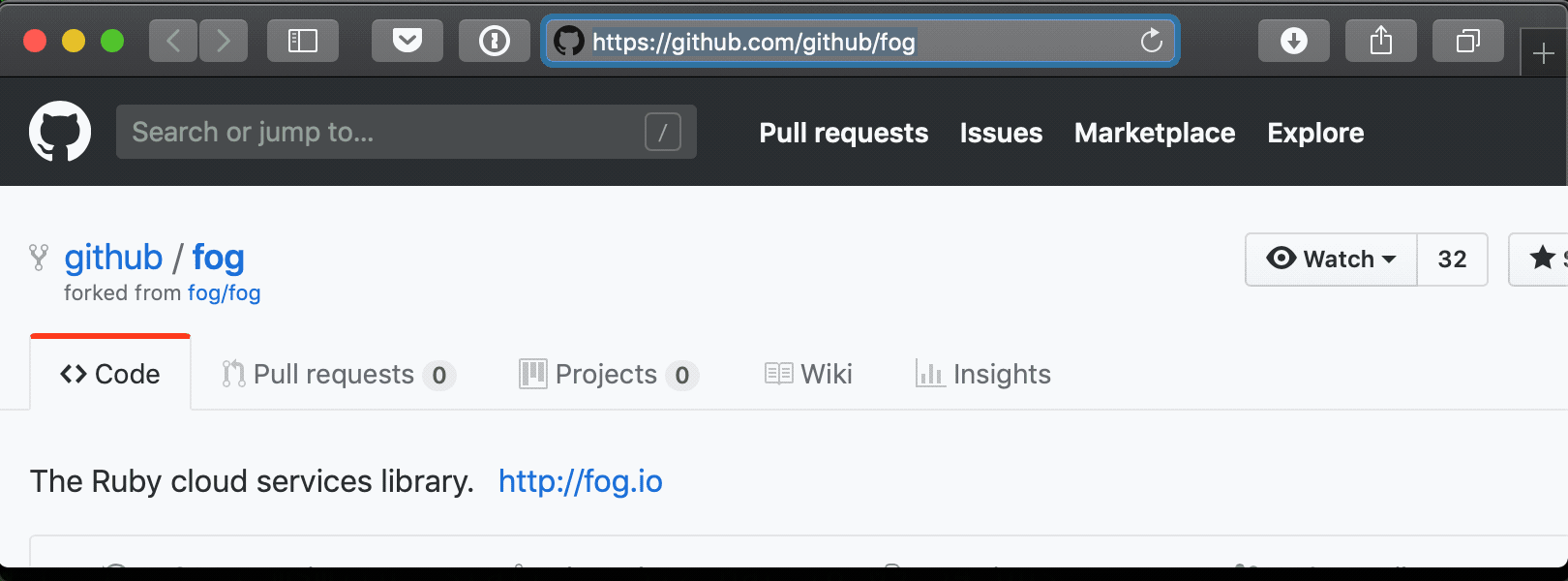
function fhub
listrepo_gql (cat $HOME/.github_patoken) github | fzf | read -l repo
if test -n "$repo"
echo "Opening '$repo' in Web Browser"
hub browse $repo
end
end
Results
Schweeet
Afterwards. I took another pass at making this even faster.